

Ce 6 novembre OpenAI a rendu accessible gpt-4-vision-preview aussi appelé GPT-4V ouvrant (entre autres) un nouveau champs des possibles aux développeurs sur la manipulation et l’analyse des images. Au cours de cet article nous allons vous partager différents cas d’usage que nous avons testé, pour appréhender les fonctionnalités et les limites de cette preview.
Dans cet article nous n’aborderons pas DALL·E 3 qui est aussi une des fonctionnalités ajoutée à l’API Image ce 6 novembre. Pour rappel, ce modèle dall-e-3 permet notamment de générer des images sur base d’un prompt.
GPT-4 Vision, qu’est-ce que c’est ?
GPT-4V est un modèle qui permet d’interroger et d’extraire des informations d’une image. GPT-4 Vision est aussi capable de traiter un ensemble d’images, ainsi qu’une suite d’images. Ce modèle repose sur GPT-4, il est donc possible de faire interagir les données extraites des images avec d’autres données et surtout de les enrichir.
Les limites de GPT-4 Vision
En détaillant ses limites, OpenAI met en garde quant à la capacité du modèle à être pertinent dans certaines situations. Voici les cas d’usage référencés pour lesquels GPT-4 Vision ne seraient pas des plus efficaces :
- Interprétation d’images médicales ;
- Reconnaissance d’alphabets non latins ;
- Raisonnement spatial ;
- Comptage d’objets ;
- CAPTCHA’S (on comprend pourquoi) ;
- …
Dans certains cas, ce n’est pas tant la technologie qui est un frein mais bien OpenAI qui a décidé de limiter les capacités de son IA. Propriétés privés, reconnaissance facial, données sensibles sont autant d’arguments que l’IA a avancé pour certains de nos tests.
Comme nous sommes curieux, on a voulu tester par nous-mêmes sur des cas plus ou moins avancés.
- Nous n’avons pas réussi à trouver Charlie (Waldo).

Lorsqu’on a demandé à ChatGPT de trouver Charlie, l’IA s’est lancée dans une mission qui semblait à la fois simple et complexe. Après tout, ChatGPT est capable de répondre à une multitude de questions, de générer du contenu de qualité, et même de résoudre des problèmes mathématiques complexes. Alors, pourquoi la recherche de Charlie serait-elle un défi ?
Après pas mal de prompts et en lui soumettant des idées d’algo pour résoudre le problème, ChatGPT a fini par nous proposer des coordonnées, mais malheureusement erronées.

On a même testé une board plus simple, même résultat. L’IA nous a dit que l’humain était plus efficace sur ce type d’analyse. La réponse réside dans la nature de l’énigme de Charlie. Trouver ce personnage demande une perception visuelle aiguisée, la capacité de repérer des détails subtils et une grande dose de patience. Autant de compétences qui sont à la portée des êtres humains, mais qui restent un défi pour les IA. D’un point de vue technique on a pu constater que l’IA a tenté la reconnaissance de forme précises telles que les rayures du pull-over de Charlie, mais sans doute trop précises pour matcher.

2. Nous n’avons pas réussi à compter le nombre d’occurrences de piscines.

Toujours dans l’analyse d’image, compter le nombre de piscines peut sembler être une tâche anodine, mais cela peut s’avérer beaucoup plus complexe qu’il n’y paraît. Pourquoi ? Parce que les piscines ne se limitent pas à un seul type ou à une seule taille. Il existe une variété infinie de formes, de styles, de couleurs et de tailles de piscines. De plus, une vue satellite fait varier la qualité des images en fonction du zoom choisi par l’utilisateur… Mais nous avons été confronté à une objection tout autre.
On a réussi à contourner la limitation basée sur les propriétés privées, mais le résultat est resté le même. ChatGPT a tenté l’exécution de librairies (cv2) non disponible dans son environnement d’exécution.
3. Nous n’avons pas réussi à extraire les informations figurant sur une carte bancaire.

Certaines informations figurant sur une carte bancaire, telles que les numéros de carte, les dates d’expiration et les codes de sécurité, sont sensibles et sécurisées. L’accès à ces informations est strictement réglementé pour des raisons de sécurité et de protection des données.

Des limites oui, mais globalement c’est scotchant.
- Nous avons réussi à extraire les produits d’une plano merch et analyser la présence des marques au sein d’un rayon de magasin.

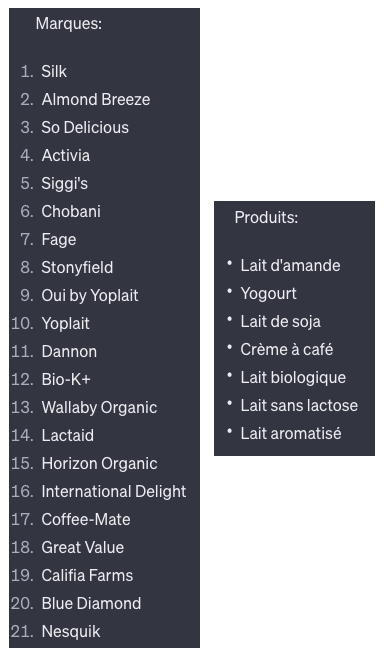
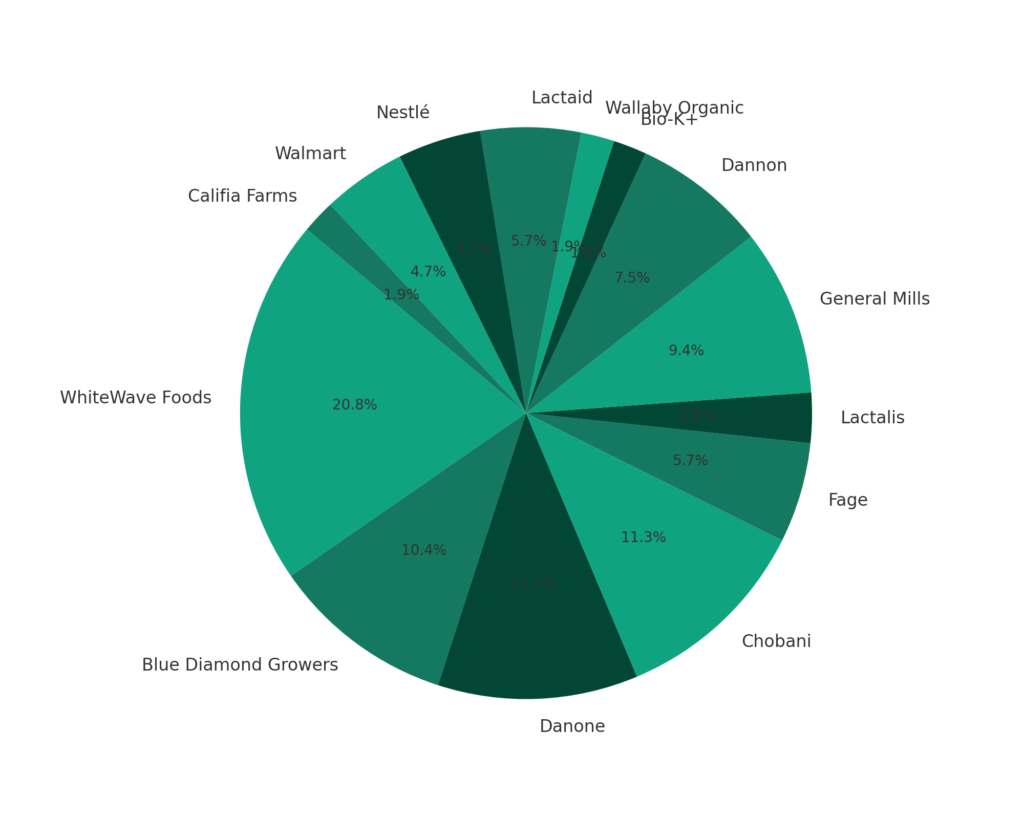
Et on a même pu faire un rapprochement avec leurs sociétés mères respectives pour détecter la présence des marques sous forme de PieChart. Ci-dessous le graphique brut. On constate qu’un travail plus approfondit sur le prompt serait nécessaire pour traiter les cas de type « Dannon » vs « Danone » qui s’apparente à un problème de détection de caractère avec l’OCR ou l’IA.
2. Nous avons généré des méta-données sur une photo produit pour un site e-commerce, les résultats sont au rendez-vous.


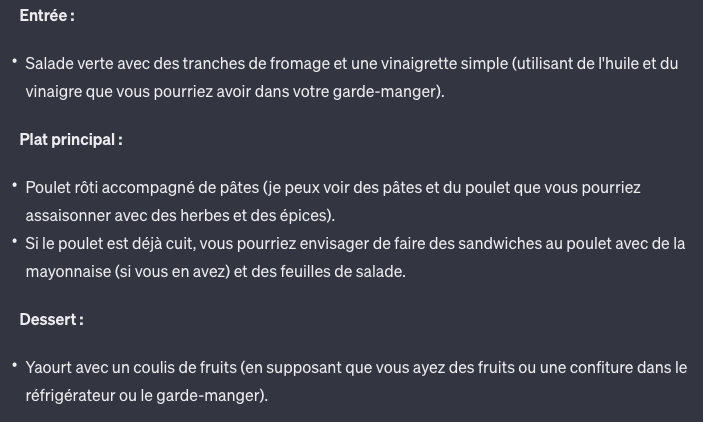
3. Nous avons généré un menu avec les aliments présents dans notre réfrigérateur.

Le fameux use case… mais comme on aime tester… Figurez-vous que ça n’a pas été très fluide, il a fallut lui préciser à plusieurs reprises que certains éléments proposés dans le menu n’étaient pas dans le frigo.
4. Nous avons testé l’OCR avec la lecture de tickets de caisse.


C’est un début. Un des 3 tickets n’est tout simplement pas traité, car assez spécifique : il s’agit d’un ticket de parking.
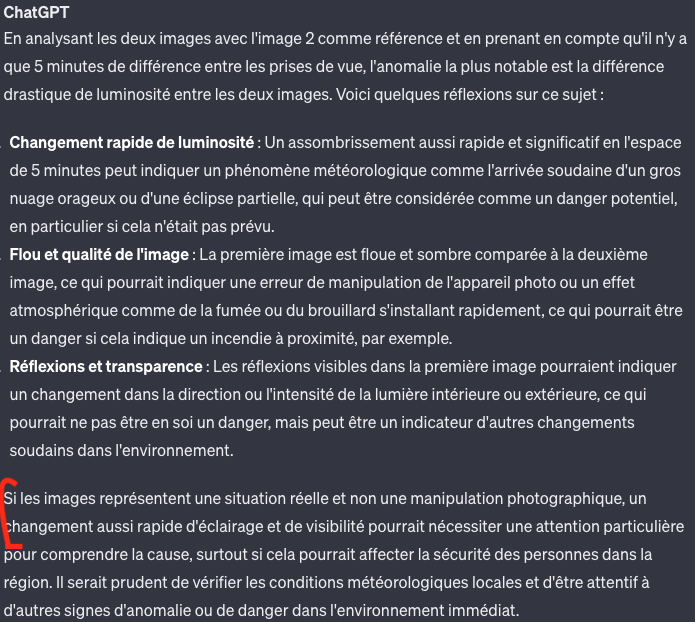
5. Nous avons comparé deux images et challenger l’IA.
Notamment avec une photographie sans et avec fumée pour voir si par elle même elle était capable de déceler une anomalie. Peut-être la place à une nouvelle génération de capteur IoT (pompe de relevage, alarme incendie, détection de chute…) pilotés par Webcam + IA.

6. Nous déchiffré une partition de musique.

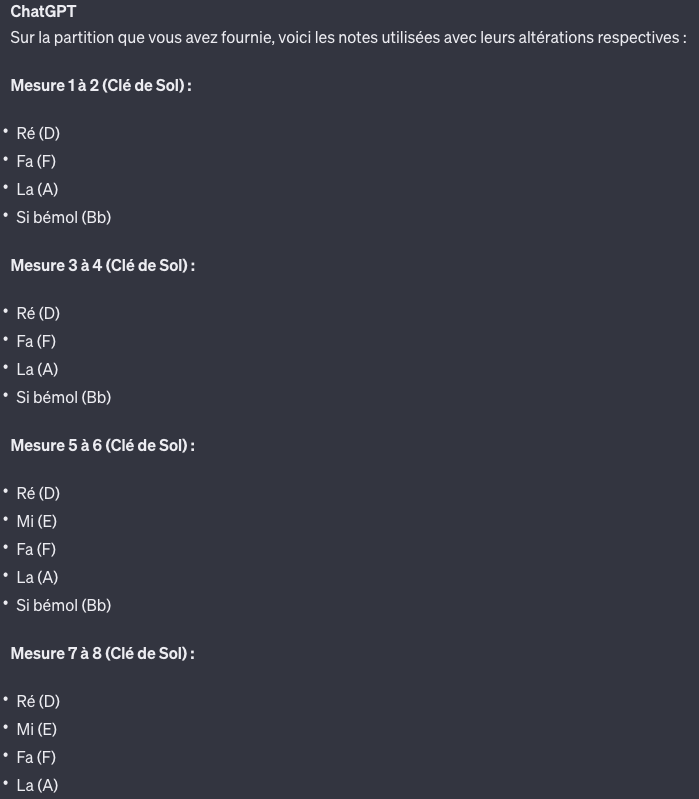
Visiblement l’IA n’est pas très piano, elle a tout simplement ignoré la clé de FA. On notera tout de même que la détection de bémols à la clé ainsi que la décomposition en mesures est pris en compte. On a tenté de transposer et de générer une nouvelle partition, mais la génération d’une partition n’est pas possible pour le moment.
7. Nous avons généré une documentation explicative d’un schéma d’architecture.
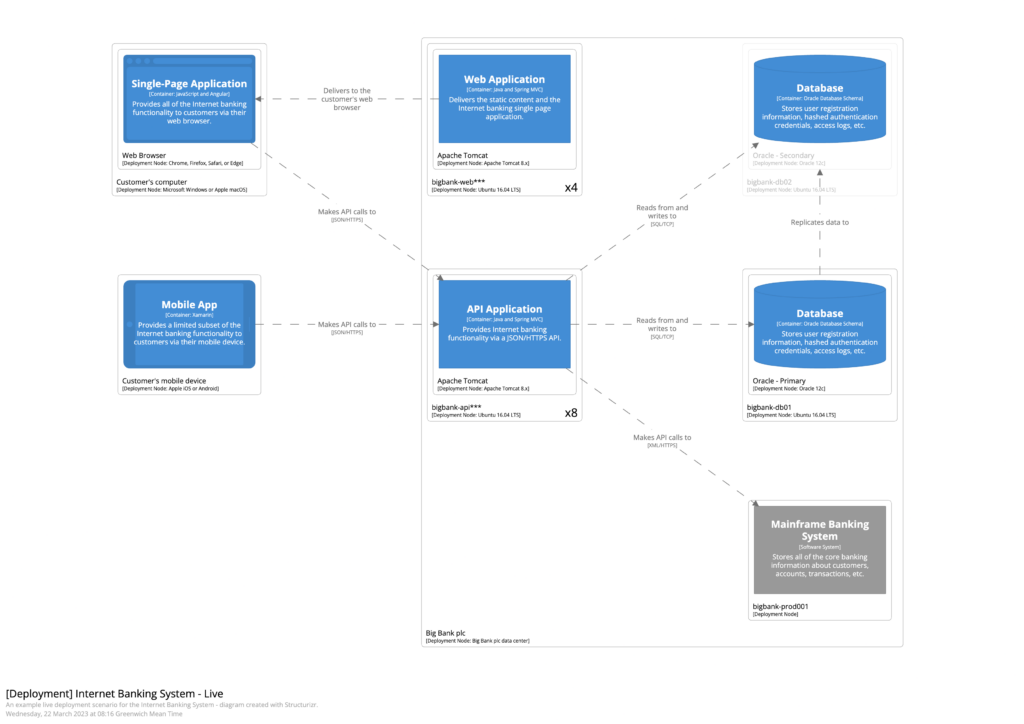

…
Globalement, nous avons constaté que cette API se veut très précise dans ses réponses. En effet, elle préfère ne pas répondre à une question si le résultat est approximatif. Au cours de nos tests, nous avons souvent dû arrondir les angles au niveau des prompts afin d’obtenir des résultats.
Les images c’est bien, mais qu’en est-il de la vidéo ?
À ce jour GPT-4 Vision accepte exclusivement des fichiers de type images : PNG, JPG, WEBP et GIF non animé. Pour autant, le modèle pouvant analyser un ensemble d’images (cf. notre comparaison de photos ci-dessus) il est possible d’analyser une vidéo. La mise en œuvre sera plus contraignante car vous devrez traiter la bande son en parallèle et faire du frame par frame. Pour aller plus sur la mise en oeuvre technique et l’export d’images sur base d’une vidéo, consultez cet article de Kay Chen.
Vais-je pouvoir créer un assistant (bot) qui analyse des images ?
À terme oui c’est une évidence, mais à ce jour l’API Assistants qui permet notamment de créer des assistants (semblables aux GPTS) ne supporte pas les images en entrée. Attention, il n’est pas nécessaire de passer par l’API Assistants pour proposer ce service.
Curieux de voir l’IA en action ? Cliquez ici pour un voyage saisissant au cœur de « 11 Applications Innovantes avec OpenAI GPT-4 Vision ». Plongez dans un monde d’innovations et d’applications concrètes qui façonnent l’avenir de la technologie.
Vous pensez qu’OpenAI et plus généralement l’IA peut booster votre business ? C’est peut-être l’occasion de faire un POC ? Contacter-nous pour analyser ensemble la faisabilité et la mise en œuvre de ce type d’API au sein de votre entreprise.


